오늘의 학습 동영상
https://www.youtube.com/watch?v=ZTJjW7XuHIY&list=PLU9-uwewPMe2-vtJAgWB6SNhHcTjJDgEO
학습 기록
1. Groom IDE 사용법
클라우드 기반의 IDE
무료 버전으로 최대 5개까지 container 생성 가능
2. Beautifulsoup 라이브러리 기초
웹크롤링을 하기 위해 html 태그를 parsing 해주는 라이브러리
특정 태그 또는 클래스 아이디로 원하는 내용만 크롤링 할 수 있음
-> 원하는 내용만 얻기 위해 클래스 아이디의 규칙성을 파악해야함
-> find(), find_all(), select() 등이 있음 --------------------------------- [참고1]
3. 크롤링 하고 파일에 저장하기
'python write text file' 구글에 검색해서 복붙해서 쓰기
4. 크롤링이 됐다가 안 됐다가 한다
-> 아래에 있는 '이 사이트는 로봇이군'이라고 판단한 서버측에서 발생시키는 오류
-> 아래에 해결법 있음 ------------------------------------ [참고2]
5. google-image-download 라이브러리
이건 조코딩 영상이 3년 전꺼라 발생한 오류
찾아보니 구글에서 이미지 크롤링하려면 기존 라이브러리 말고 다른 경로로 설치해야한다고 함
-> 근데 다른 방법으로도 안 돼서 일단 포기...
-> 다음 수업으로 '셀레니엄 라이브러리' 에서 이미지 크롤링 학습 계속하기
여차저차 완성한 프로그램
=> 네이버 사이트에 있는 main-left 조그만 영역 중 웹툰 영역에서 '웹툰 제목'만 가져와서 새로운 텍스트 파일에 저장하기
from bs4 import BeautifulSoup
from urllib.request import urlopen
response = urlopen('https://www.naver.com/')
soup = BeautifulSoup(response, 'html.parser')
# writedata.py
i = 1
f = open("새파일.txt", 'w')
for element in soup.select(".chart_info strong.title"):
data = str(i) + "번째 : " + element.get_text() +"\n"
i = i + 1
f.write(data)
f.close()
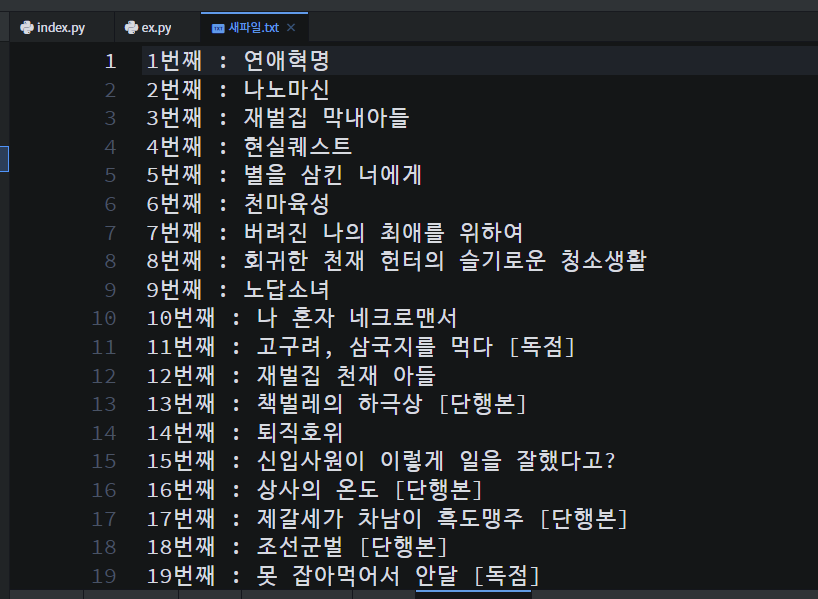
응용해보자구
[1] 멜론 웹사이트에서 '멜론차트 100개 노래 제목'을 크롤링
1. 406 http 에러 발생

: 웹사이트가 크롤링하려는 것이 기계인 줄 알고 발생시키는 오류
-> '나는 사람이야!'를 알려주기 위해 User Agent Information 발급 후 해결함
2. 뭔가 좀 어려워짐
조코딩에서 배운 것보다 조금 난이도 있는 것을 도전해버렸나..
여기저기 오류 터지고 몰라서 검색하고 복붙하고 하다보니 내가 지금 뭘 하고 있는건지 이게 왜 이렇게 되는건지 흐름을 놓쳐버림..
3. 이렇게 저렇게 해봤는데 결국 오류의 원인은 '오타' 95%...
하루종일 붙잡고 씨름했는데 결국 오타가 원인이었다.. 정말 개발자는 인내심이 너무 필요하구나
#!/usr/bin/env python3
# Anchor extraction from HTML document
from bs4 import BeautifulSoup
from urllib.request import urlopen
import urllib.request
import urllib.parse
# '나 로봇 아니야~ 사람이야~' 처리 과정
# 원래 주소를 저장하고
urladdress = 'https://www.melon.com/chart/'
# header에 Header의 Information (나 사람이야~) 넣어줌
header = {'User-Agent' :'Mozilla/5.0'}
# Header 속성에 새로운 정보를 추가한 'header' 변수로 바꿔주고 요청 url주소에 담아서 modi에 저장
modi = urllib.request.Request(urladdress, headers = header)
# '나 사람이야~' 정보를 담은 url로 요청을 보내고 beautifulsoup 객체를 이용하여 html 문서로 parsing
htmlcontent = urllib.request.urlopen(modi).read()
soup = BeautifulSoup(htmlcontent, 'html.parser')
# 노래랑 가수 크롤링해서 object에 저장
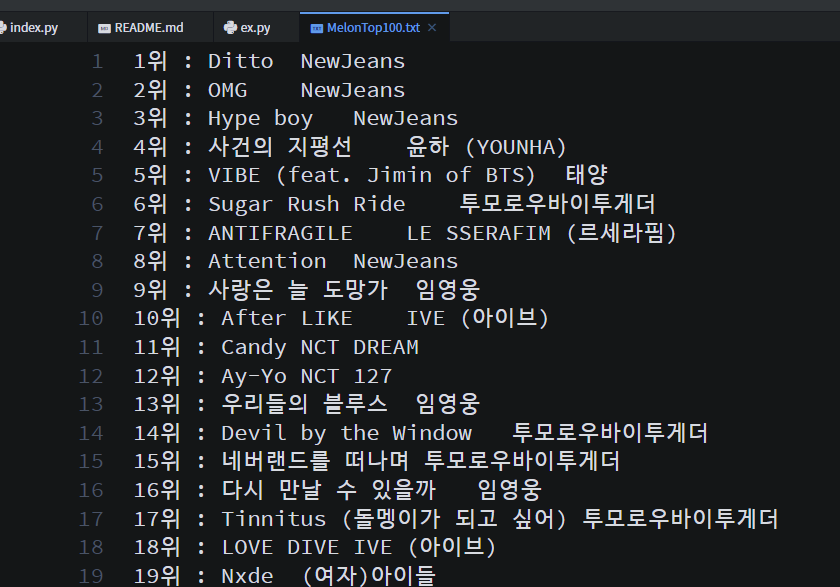
song = soup.select('.ellipsis.rank01 a')
singer = soup.select('.ellipsis.rank02 > a:nth-of-type(1)')
# 크롤링한 것을 저장할 파일을 만들고
f = open("MelonTop100.txt", 'w')
i = 0
for i in range(len(song)):
data = str(i+1) + "위 : " + song[i].get_text() + "\t" + singer[i].get_text() + "\n"
f.write(data)
i = i + 1
f.close()Top 100 순위, 노래, 가수를 'MelonTop100.txt' 에 크롤링하여 만들어준다!
[2] Daum 사이트에 '경제' 뉴스에서 헤드라인 크롤링
from bs4 import BeautifulSoup
from urllib.request import urlopen
response = urlopen('https://news.daum.net/breakingnews/economic/finance')
soup = BeautifulSoup(response, 'html.parser')
title = soup.select(".tit_thumb .link_txt")
content = soup.select(".desc_thumb .link_txt")
page = 1
num = len(title)
f = open("경제뉴스.txt", 'w')
for i in range(num):
head = title[i].get_text()
body = content[i].get_text().lstrip()
data = head + "\n" + body + "\n\n"
f.write(data)
f.close()보완할 점 : 페이지 넘기면서 원하는 기사의 수만큼 한 번에 크롤링 하기

참고 사이트
1. 클래스 아이디, 태그만 골라주는 함수 사용법
https://computer-science-student.tistory.com/235
[파이썬, Python] BeautifulSoup으로 크롤링(crawling)(2) - select() 옵션
BeautifulSoup의 find(), find_all(), .string, get_text()에 이어서 BeautifulSoup의 select() 함수에 대해 알아보자! select() 함수를 사용하여 원하는 데이터 추출 find() 함수와 find_all() 함수를 이용하여 원하는 태그를
computer-science-student.tistory.com
2. 멜론차트 크롤링 오류 해결 참고 사이트
Python 파이썬 HTTP Error 406 : Not Acceptable 솔루션 User Agent 선언 + 멜론 차트 크롤링 하기
안녕하세요, 오늘 포스팅 할 내용은, 크롤링 시, 저희가 원하는 HTML 내용이 잘 안가져 와지는 현상 및 멜론 차트 100곡을 크롤링하는것에 대해서 포스팅 하려고 합니다. 멜론 차트 100곡을 크롤링
davey.tistory.com